Thoạt đầu
Cho những ai hay đọc blogs của mình thì nay mình lại ngoi lên để chia sẻ một số kiến thức kinh nghiệm hiện có. Xin chào, mình là GluTis một sinh viên ngành toán tại Hust. Trong thời gian đi thực tập vừa qua mình có gặp một vài kiến thức khá thú vị, khá hay nữa. Lần đầu có cái công thức mình ngồi nghe cả buổi mới hiểu. Nó không phải là các công thức kinh tế mà tôi thường gặp, không phải đạo hàm, tích chập và cũng chả có những phép toán nào quá phức tạp, chỉ đơn giản là các phép toán đại số trên một không gian 2 chiều. Là các công thức liên quan đến các chỉ số trong kinh doanh của một doanh nghiệp tại một bài toán cụ thể.

–> Để hiểu và không làm mất kiến thức của bản thân thì blog này được ra đời :>
Mình có nhận một task là làm một bảng dữ liệu để đội DA có tạo các dashboard dữ liệu theo đó. Nếu bạn học môn học DW & BI rồi thì chắc các bạn sẽ ko còn xa lạ gì với các chart cohort (đa phần các bài được điểm cuối kỳ cao đều là do sử dụng chart này - có thể là do thầy rất thích những chỉ số mang tính so sánh)
Cohort là một loại chart đem lại ý nghĩa to lớn trong kinh doanh, nó cho ta cái nhìn tổng quát các ngày phía sau so với ngày ban đầu. Hãy cùng tham khảo một ví dụ tôi tìm được trên mạng.
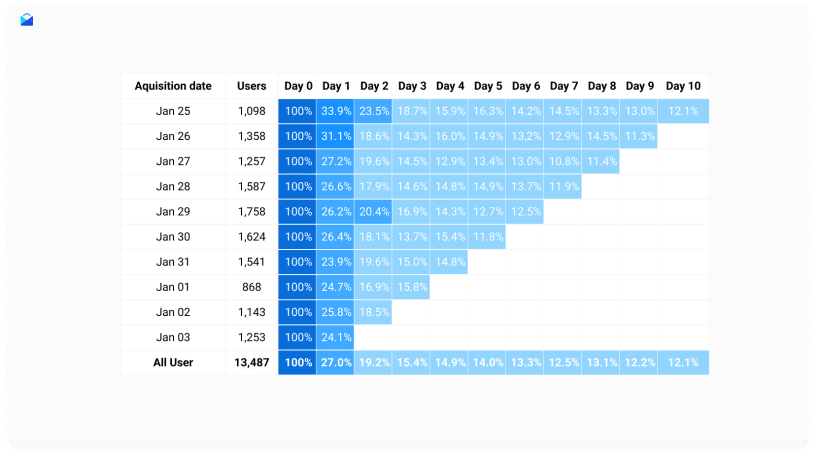
Nhìn vào một bảng cohort như này boss có thể đánh giá được theo từng ngày. Hiểu được hành vi của người dùng theo thời gian và thường là trong một gói kinh doanh nào đó (gọi là gói cho nó giống tính bao đống của package trong phân tích thiết kế hệ thông chứ mình không có định nghĩa cụ thể)
Ý Nghĩa Của Phân Tích Chart Cohort:
-
Theo Dõi Retention Rate: Giúp hiểu rõ tỷ lệ giữ chân người dùng theo thời gian và xác định những giai đoạn mà người dùng thường xuyên rời bỏ dịch vụ.
-
Đo Lường Hiệu Quả Chiến Dịch: Cho phép doanh nghiệp đánh giá hiệu quả của các chiến dịch marketing hoặc cải tiến sản phẩm bằng cách so sánh hành vi của các cohort khác nhau.
-
Phát Hiện Vấn Đề: Giúp nhận diện các vấn đề hoặc thách thức mà người dùng gặp phải tại các thời điểm cụ thể trong hành trình sử dụng sản phẩm hoặc dịch vụ.
-
Tối Ưu Hóa Sản Phẩm: Cung cấp thông tin chi tiết để doanh nghiệp điều chỉnh và tối ưu hóa sản phẩm hoặc dịch vụ nhằm cải thiện trải nghiệm người dùng và tăng tỷ lệ giữ chân.
-
Đưa Ra Quyết Định Dữ Liệu: Hỗ trợ các quyết định dựa trên dữ liệu thực tế về hành vi của người dùng thay vì dựa vào cảm giác hoặc phỏng đoán.
Không luyên thuyên nữa, bây giờ ta sẽ đi vào các metric chính.
Retention® - tỷ lệ giữ chân khách hàng ở lại
Để đánh giá tỷ lệ khách hàng quay trờ lại sử dụng dịch vụ thì các ông lớn kinh doanh nghĩ ra cái chỉ số hay ho này. Nói dễ hiểu là như này, boss bỏ ra 500 xèng để mời được một anh A đến cửa hàng của mình để mua hàng (bao gồm đủ loại chỉ phí marketing, …). Boss muốn biết là các hôm sau thì khách hàng này còn đến và đem lại doanh thu ra sao.
Ngày đầu anh A này đến và chỉ bỏ ra 50 xèng để mua 1 bộ quần áo - tính ra boss lỗ 450k trong ngày đầu.
Hôm sau anh ta lại quay lại, lần này A chi mạnh tay hơn để mua một bộ Gucci 150k - Với ngày 2 boss lại được 150k mà ko phải bỏ ra chi phí gì nhưng thực chất boss đang lỗ 300k. - đây là tôi đang giả sử nhé chứ sao mà lãi đc 150k luôn đc :V
Tương tự như vậy các hôm sau, boss ko phải bỏ ra chi phí gì nhưng khách hàng vẫn quay lại và tiếp tục đem lại doanh thu. Và boss muốn biết là khách hàng quay lại và đem lại doanh thu ra làm sao.
Đây là một ứng dụng cho triết lý:
Sẵn sàng chấp nhận lỗ để có doanh thu (re) trong các ngày sau.
Giả sử:
- ngày 1 số user sử dụng app là 1000 (event_name = “first_open”).
-> lúc này R0 = 1 (hiển nhiên là không có khách hàng nào rời bỏ dịch vụ do R chỉ so sánh với ngày đầu)
- ngày 2 số user ngày ngày đầu tiên (event_name = “first_open”) và có event_name = “session_start” vào ngày thứ 2 là 500 (tất nhiên là phải nhỏ hơn hoặc bằng ngày đầu)
-> lúc này R1 = = 0.5 = 50%
- ngày 3 số user hoạt động vào ngày 3 nhưng có event_name = “first_open” vào ngày 1 là 200 (tất nhiên là phải nhỏ hơn hoặc bằng ngày 2)
-> lúc này R2 = = 0.2 = 20%
Cứ vày cho các ngày tiếp theo.
-> R là 1 hàm nghịch biến, khi tăng ngày thì R luôn giảm
Đồ thị Retention

Nếu mình họa dưới dạng query thì nó sẽ trông như vầy:
Tính tổng user dùng app trong ngày đầu (tổng quát)
1 | SELECT event_date, COUNT(DISTINCT user_pseudo_id) |
_TABLE_SUFFIX là một lệnh đặc biết chỉ có trong Big Query cho phép bạn làm việc với các bảng được phân đoạn theo ngày hoặc các bảng có hậu tố tên tương tự
Ví dụ cụ thể
Truy vấn các bảng với hậu tố cụ thể: Giả sử bạn có các bảng nhật ký hàng ngày với tên dạng logs_YYYYMMDD và bạn muốn truy vấn dữ liệu từ bảng logs_20230729.
1 | SELECT * |
Truy vấn nhiều bảng trong một khoảng thời gian: Nếu bạn muốn truy vấn các bảng nhật ký từ ngày 2023-07-01 đến ngày 2023-07-31, bạn có thể sử dụng điều kiện _TABLE_SUFFIX với một phạm vi cụ thể.
1 | SELECT * |
Nếu chỉ tính một ngày thì chỉ cần cout distinct là ok.
2 ngày liên tiếp
1 | select count(distinct user_pseudo_id) |
-> Ý tưởng là dùng một truy vấn lồng để lấy In user_pseudo_id trong ngày đầu.
Tổng quát cho tất cả các ngày
1 | WITH first_open_users AS ( |
Life time Value(LTV)
Hãy tưởng tượng bạn đang kinh doanh một cửa hàng mĩ phẩm, bạn đầu tư rất nhiều tiền cho các hoạt động digital marketing để thu hút khách hàng. Làm sao để biết được khách hàng mà bạn thu hút được có tương xứng với các chi phí mà bạn bỏ ra. Đó là lúc bạn cần biết LTV Metric (Giá trị vòng đời của khách hàng.)
-> Dùng 500 xèng thu hút 1 cô gái đến mua mĩ phẩm, sau 5 ngày cô ấy đến mua và chi tiêu hết 550 xèng. Nghĩa là bạn đã có lãi 50 xèng.
-> Metric này cho biết tổng số tiền kỳ vọng của một khách hàng sẽ chi trả cho doanh nghiệp của bạn trong suốt vòng đời khách hàng của họ
Đồ thị LTV
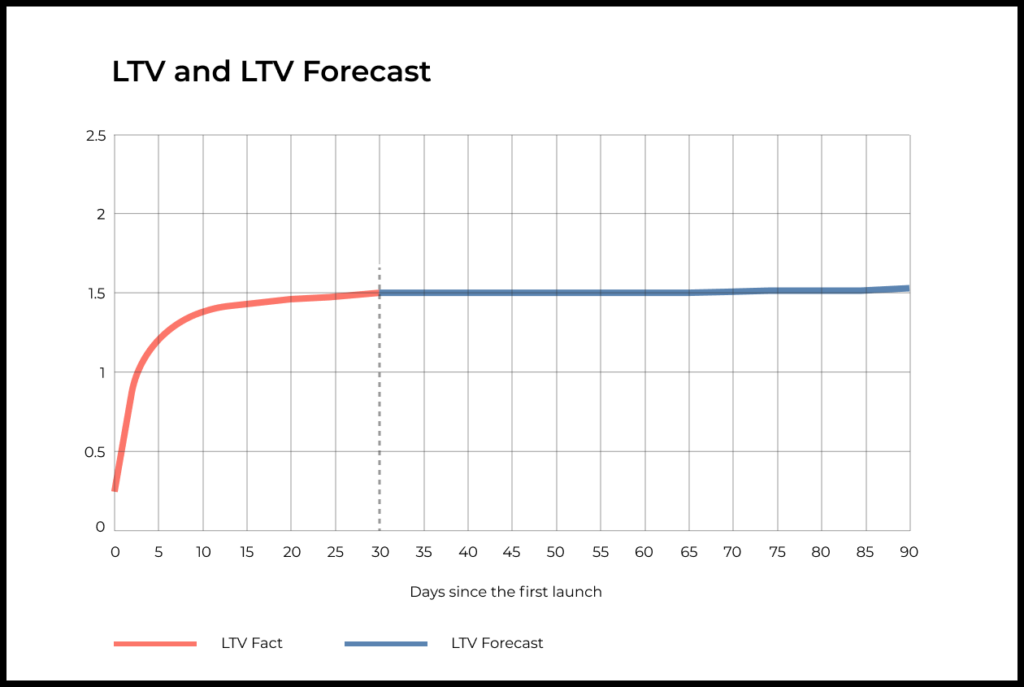
Để tính thì mình chỉ cần nghĩ đơn giản là: ngày 1 khách hàng quay lại bao nhiêu đó là LTV của D1, D2 khách hàng quay lại bao nhiêu phải + khách hàng quay lại ngày 1, tương tự với D3:
LTV_D1 = tổng những khách hàng có event_name = “session_start” ngày 1 với điều kiện có event_name = “first_open” ngày 1
LTV_D2 = tổng những khách hàng có event_name = “session_start” ngày 2 với điều kiện có event_name = “first_open” ngày 1 + LTVD1
LTV_D3 = tổng những khách hàng có event_name = “session_start” ngày 3 với điều kiện có event_name = “first_open” ngày 1 + LTVD2
tính cho 2 ngày liên tiếp
1 | ``` |
Churn©- Tỷ lệ khách hàng rời bỏ dịch vụ
Kỳ trước mình có sp một ông bạn làm bài toán dự đoán khách hàng rời bỏ.
- Đầu vào của mình là một bảng dữ liệu gồm khoảng 30 cột, sau khi tiền xử lý và đánh giá tương quan thì đem lại 14 cột có tương quan > 0.3 một chỉ số chấp nhận được để huấn luyện mô hình dự báo.
- Đầu ra là ứng với mỗi bản ghi có đầy đủ các thông tin trong 14 cột trên và mô hình đưa ra kết luận là khách hàng đó có rời bỏ dịch vụ hay không. Áp dụng 15 thuật toán machine để đánh giá. Thì theo như thống kê thì random forest và knn là các kĩ thuật đem lại độ chính xác cao cho mô hình (đi qua nhiều layer)
Ngày đó mình biết về chỉ số này thì đã tăng được độ chính xác cho mô hình đó rồi :)))
Cùng một bài toán tương tự với các chỉ số trên: Có một cái app, xếp muốn mình phải đo tỷ lệ khách hàng rời bỏ dịch vụ so với ngày đầu tiên (cái gì cx so với ngày đầu nha) có event_name = “app_remove” gọi là tắt AR.
- ngày 1 có 1000 user tải app. và 200 user xóa app
- ngày 2 có 200 user xóa app và có event_name = “first_open” như ngày đầu.
- ngày 3 có 300 user xóa app và có event_name = “first_open” như ngày đầu.
Thì công thức cụ thể cho trường hợp này là:
Ngày 1:
Churn_D0 =
-> Viết theo ngôn ngữ tự nhiên thì: tỷ lệ khách hàng rời bỏ dịch vụ ngày đầu sẽ bằng tổng số user có AR ngày đầu trong điều kiện có “first_open” ngày đầu
Vậy những ngày tiếp theo thì thế nào, ngày 2:
Churn_D0 = + churn_d0
-> Số khách hàng rời bỏ dịch vụ ngày 2 tất nhiên phải cộng cả ngày thứ nhất vào, do vậy tỷ lệ khách hàng rời bỏ luôn tăng
Lời giả cho bài toán trên:
Churn_D0 = 0.2
Churn_D1 = 0.4
Churn_D2 = 0.7
Đồ thị Churn

Mọi người có thấy điểm gì lạ ở đây không. Đó là vào ngày đầu tiên thì khách hàng vừa có thể mở app vừa có thể xóa app luôn ngay sau đó. Như xóa đi xong tải lại - user_id vẫn được giữ nguyên do đã được định danh theo căn cước từ trước.
Có thể bạn vẫn khó hiểu thì tôi xin có một ví dụ như sau: xóa db đi tạo lại thì chỉ có log khác đi thôi còn người tạo vẫn là chủ tài khoản đấy thôi — rất chi là điển hình.
Cho 2 ngày liên tiếp
1 | session_start_events AS ( |
-> Đơn giản là lấy giao và áp dụng truy vấn lồng như trên, các ngày sau thì cộng thêm ngày trước đó là được.
Tổng quát cho tất cả các ngày
1 | WITH first_open_users AS ( |
 bank
bank- bank