Tại sao có bài viết này
Sơ lược
Xin chào ! Mình là Glutis - Một sinh viên ngành toán tại HUST, vài tháng gần đây loay hoay đau đầu với nhiều lỗi lo của các sinh viên sắp ra trường, mình càng thấm thía hơn câu nói của một giám đốc trung tâm tiếng anh từng chia sẻ
“Năm nhất bận thì chắc chắn năm 2 năm 3 sẽ càng bận hơn”.
Quả đúng vậy bao thứ ập đến, ủa vây lấy tôi từ công việc, gia đình, bạn bè, rồi việc trường lớp, khởi nghiệp lọ kia. Ta loay hoay giữa một vùng trời lớn, ta đắn đo suy nghĩ chẳng biết đi về đâu. Những áng trời đẹp đẽ mây trôi vô định chẳng còn hiện trong ánh mắt cậu học trò này mà thay vào đó là sự trĩu nặng trách nhiệm và kỳ vọng. Giờ đây, mình không còn là một cậu học trò chỉ cần học tốt là xong – mà đã thực sự bước vào guồng quay của một “thế giới tư bản” đúng nghĩa.
Tôi thực tập tại một công ty Outsource cho khách hàng người Nhật trong 2 tháng, tổng quan thì tôi thường làm về dữ liệu và Machine Learning là một trong những cái mà tôi hay làm và mang võ công này đi rất nhiều các cuộc thi. Từ những ngày còn chập chững được các anh trong lab cầm tay chỉ từng dòng công thức toán đến những giờ seminar căng thẳng. Tưởng đâu với machine learning tôi đã vững chắc lắm rồi. Rồi đời cũng vả mặt tôi bằng một bài toán khó.
Chả là, tôi cần luyện một model để dự đoán các công ty tại Nhật Bản để làm giàu dữ liệu cho công ty, nghĩ mà xem có data một công ty khác mà còn là dữ liệu revenue thì thật là kinh khủng, dữ liệu doanh thu để huấn luyện mô hình thì lại rất ít.
Vấn đề là ở đây: dữ liệu doanh thu thì lại cực kỳ khan hiếm. Thường thì ae làm model dữ liệu thường phải lên đến vài triệu đến vài tỉ dòng, không thiếu, muốn trường gì có trường đó thiếu thì kêu người ta đi lấy về, trong trường hợp của tôi thì lại khác các ông ạ! Data nó tí tẹo có 40k dòng xong còn null nhiều vaiz chưởng, kêu gọi đi lấy thêm data về thì khó do dữ liệu doanh thu public rất ít. Mà crawl về thì khó cơ. Ấy vậy mà problem thì ta vẫn phải resolve thôi!
Kể cũng ác, cty crawl được data của hơn 5,5tr công ty Nhật mỗi công ty hơn trăm fields
Vậy đó, dữ liệu thì ít, task thì khó, nhưng mô hình thì vẫn phải training, kết quả vẫn phải ra. Chạy đâu cho khỏi cái task này!
Xem tôi giải quyết nó như nào nhé!
Các thách thức
a) Vấn đề chất lượng dữ liệu: Dữ liệu bị thiếu, định dạng không đồng nhất, thiếu sự tích hợp giữa các phòng ban.
b) Overfitting (quá khớp): Đặc biệt xảy ra với dữ liệu có nhiều chiều hoặc kích thước mẫu nhỏ.
c) Khó giải thích: Các mô hình phức tạp như mạng nơ-ron thường hoạt động như một “hộp đen”.
d) Thị trường thay đổi nhanh chóng: Các mô hình huấn luyện từ dữ liệu quá khứ có thể không còn hiệu quả trong thị trường biến động mạnh (ví dụ: đại dịch COVID-19).
e) Thiên lệch trong dữ liệu: Dữ liệu sai lệch hoặc mất cân bằng có thể dẫn đến dự đoán không chính xác.
Sơ lược về bộ dữ liệu
Dữ liệu gồm 5.5 tr dòng, trong đó có 40k dòng là các công ty có revenue dùng để luyện model. Số còn lại không được public, các trường dữ liệu có thể sử dụng được bao gồm (hơn trăm trường nhưng đa số null và không có tác dụng):
- corporate_number: Mã số doanh nghiệp duy nhất, dùng để định danh công ty.
- employee_count: Số lượng nhân viên hiện tại trong công ty.
- capital: Vốn điều lệ hoặc vốn đầu tư đăng ký của công ty.
- business_model_codes: Mã hóa các mô hình kinh doanh mà công ty hoạt động.
- listing_market_code: Mã sàn giao dịch chứng khoán (nếu công ty đã niêm yết).
- postal_code: Mã bưu điện nơi công ty đặt trụ sở.
- establish_date_normalized: Ngày thành lập công ty đã được chuẩn hóa định dạng (ví dụ: YYYY-MM-DD).
- establish_date_normalized_updated_at: Thời điểm dữ liệu ngày thành lập chuẩn hóa được cập nhật gần nhất.
- prefecture: Tỉnh hoặc khu hành chính cấp tỉnh (ví dụ: Tokyo, Osaka…).
- city: Thành phố hoặc quận nơi công ty đặt trụ sở.
- business_content: Nội dung mô tả hoạt động kinh doanh chính của công ty.
- establish_date: Ngày thành lập ban đầu (có thể chưa chuẩn hóa định dạng).
- average_age: Độ tuổi trung bình của nhân viên trong công ty.
- average_salary: Mức lương trung bình của nhân viên (thường tính theo năm).
- group_employee_count: Tổng số nhân viên trong toàn bộ tập đoàn (nếu công ty thuộc một tập đoàn).
- management_tools: Các công cụ/phần mềm quản lý được công ty sử dụng (ví dụ: ERP, SAP…).
- communication_tools: Công cụ giao tiếp nội bộ như Slack, Microsoft Teams, Zoom…
- tech_databases: Hệ quản trị cơ sở dữ liệu mà công ty sử dụng (như MySQL, PostgreSQL…).
- revenue: Doanh thu của công ty (năm gần nhất).
- tech_clouds: Các nền tảng điện toán đám mây đang sử dụng (như AWS, Azure, GCP…).
- tech_languages: Ngôn ngữ lập trình chính được sử dụng trong công ty (Python, Java…).
- recruit_skills: Kỹ năng công ty đang tìm kiếm khi tuyển dụng (dựa theo JD).
- tech_frameworks: Frameworks công nghệ mà công ty đang sử dụng (React, Django…).
- crm_tools: Các công cụ quản lý quan hệ khách hàng như Salesforce, Hubspot…
- industry_code: Mã ngành nghề kinh doanh theo tiêu chuẩn phân loại ngành.
- nta_city_code: Mã địa phương theo chuẩn của cơ quan thuế Nhật Bản (NTA).
- corporate_kind: Loại hình doanh nghiệp (ví dụ: công ty cổ phần, TNHH…).
- meta_keywords: Từ khóa mô tả công ty, dùng cho SEO hoặc phân tích dữ liệu.
Data này trông vậy mà lớn đến 155GB nha, đó là đã qua tiền xử lý trước rồi và duplicate data do update version. Dùng kết quả luyện từ 40k công ty để dự đoán 5.5tr công ty còn lại =)).
Tiền Xử lý dữ liệu + Feature engineering
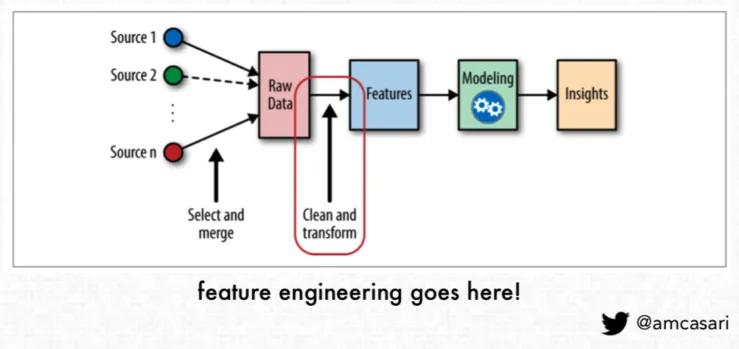
Dữ liệu đầu vào được đọc từ file CSV lớn data_after.csv được truy vấn từ trino thông qua supperset bằng cách query nhiều lần (do quá nặng) với cột ngày được chuẩn hóa về định dạng datetime:
1 | df_full = pd.read_csv(INPUT_CSV, low_memory=False) |
Giá trị nào null thì lấy trung bình cả cột,
Chia batch nhỏ để xử lý multi batch
Dữ liệu sau đó được chia thành nhiều batch nhỏ để xử lý tuần tự, đảm bảo không quá tải bộ nhớ:
1 | BATCH_SIZE = 10_000 |
Tăng cường dữ liệu với Embedding API
Mỗi doanh nghiệp có một trường mô tả business_content, được truyền vào API nội bộ sử dụng mô hình jina-embeddings-v3 để sinh ra vector đặc trưng chiều 32:
1 | def embedding(content): |
=> Phải làm thế do các feature cũ quá kém chỉ cho tương quan 0.2 trở xuống, dữ liệu cực kỳ rời rạc và nhiều ngoại lai. Cái này do CTO nghĩ rằng triết lý kinh doanh cũng ảnh hưởng rất lớn tới doanh thu.
Xử lý ngoại lai
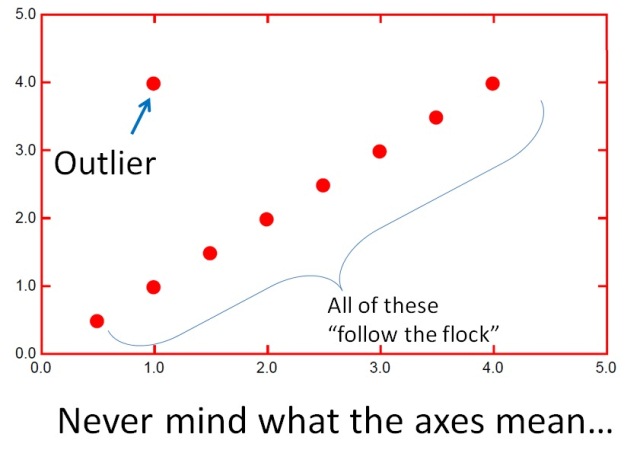
Ngoại lai
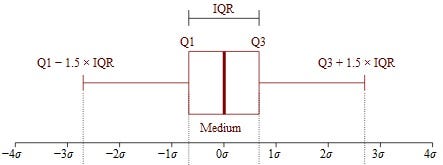
Thay thế outlier sau khi phát hiện outlier thì giới hạn giá trị về biên trên hoặc dưới:
Xử lý từng dòng dữ liệu
Mỗi dòng được xử lý qua hàm process_row() để:
-
Tính tuổi công ty từ ngày thành lập
-
Phân loại quy mô công ty dựa vào employee_count thành small, medium, large
-
Chuẩn hóa một số trường dạng text
-
Gắn thêm 32 chiều embedding (ko cần phải nén lại nữa do số chiều vẫn ít)
Kết quả trả về là một dictionary đã sẵn sàng để ghi ra file.
1 | def process_row(row): |
Model embeding được dựng trên server lớn và xây dựng theo kiểu phân tán và chạy bằng GPU, tốc độ xử lý cực nhanh, trung bình cứ 5000/phút.
Metric số lần xuất hiện trên các trang tuyển dụng

Metric này cực kỳ hữu ích cho mô hình, cũng đúng thôi công ty nào doanh thu cao thì họ sẽ đầu tư nhiều vào việc tìm kiếm nhân tài và đăng thông tin ở nhiều trang tuyển dụng khác nhau.
Mình chỉ việc dùng sql xong count số lượt xuất hiện cùng với corporate_number rồi inner join với bảng cũ. Tuy nhiên truy vấn này sẽ rất nặng và lâu.
Xử lý song song theo batch
Dữ liệu được xử lý song song với ThreadPoolExecutor, tận dụng đa luồng để tăng tốc độ xử lý API:
1 | with ThreadPoolExecutor(max_workers=20) as executor: |
Kết quả được lưu từng batch vào thư mục output_batches/:
1 | df_result.to_csv(output_file, index=False) |
Chuẩn hóa cột số
1 | scaler = StandardScaler() |
=> Khúc tạo features tôi đã tạo gần 300 feature nhưng số dùng được chắc độ 5 chục cái =))
Huấn luyện mô hình
Sau khi xử lý dữ liệu và trích xuất đặc trưng (bao gồm embedding), bước tiếp theo là huấn luyện mô hình dự đoán doanh thu (revenue). Đặc biệt, kết hợp cả đặc trưng số và đặc trưng phân loại dưới dạng embedding.
Các cột số học như capital, employee_count, company_age, v.v.
Các cột phân loại như city, prefecture, industry_code, company_scale, được mã hóa bằng embedding học được từ mạng nơ-ron PyTorch.
Toàn bộ dữ liệu được xử lý như sau:
1 | # Biến đổi categorical thành embedding |
Huấn luyện một mạng đơn giản chỉ để học biểu diễn embedding cho các trường phân loại:
Sử dụng Embedding layers
Tối ưu với Adam và MSELoss
Số epoch = 35, batch_size = 256
Sau huấn luyện, biểu diễn embedding được kết hợp với các cột số để tạo đầu vào cuối cùng:
1 | X_train_final = np.concatenate([X_train[num_cols], train_embeds], axis=1) |
Huấn luyện mô hình XGBoost
Chọn XGBoost Regressor do khả năng xử lý tốt cả dữ liệu số và khả năng kiểm soát overfitting qua early_stopping.
1 | xgb_model = xgb.XGBRegressor( |
Mô hình được huấn luyện trên dữ liệu kết hợp (số + embedding), sau đó được đánh giá bằng các chỉ số chuẩn:
-
R² (R-squared): Độ phù hợp của mô hình
-
MAE (Mean Absolute Error): Sai số tuyệt đối trung bình
-
RMSE (Root Mean Squared Error): Sai số bình phương trung bình
-
Total Relative Error: Độ sai lệch tổng giữa tổng dự đoán và tổng thực tế (truth - predict)/sum
1 | r2 = r2_score(y_test, preds_np) |
Mô hình đạt R² = 0.64 trên tập test, MAE = 3 tỷ
Làm sao để biết được tham số cho mô hình luyện ngon

Tôi dùng phần mềm explorator của bên Nhật rồi testing đủ thứ trên này rồi mới mang tham số ra cho model.
Phân tích kết quả trên tập test
Sau khi dự đoán, khớp kết quả trở lại với tập test gốc:
1 | df_test = raw.loc[test_indices].copy() |
Dữ liệu này có thể dùng cho:
-
Trực quan hóa sai số
-
Phân tích sai số theo phân khúc (company_scale, industry_code, etc.)
Lưu mô hình embedding (PyTorch)
1 | torch.save(embed_model.state_dict(), "embed_model.pth") |
Lưu trọng số mô hình embedding bằng định dạng .pth, để dễ dàng nạp lại khi cần tạo embedding từ dữ liệu phân loại mới.
Lưu mô hình dự đoán doanh thu (XGBoost)
1 | xgb_model.save_model("xgb_model.json") |
Mô hình XGBoost được lưu dưới dạng JSON, đảm bảo tính tương thích cao khi triển khai trong môi trường production hoặc phục vụ API.
Lưu pipeline xử lý dữ liệu
Các thành phần như scaler và mapping categorical đều rất quan trọng, và được lưu bằng joblib:
1 | joblib.dump(scaler, "scaler.pkl") |
Cụ thể:
-
scaler.pkl: Chuẩn hóa các cột số giống như lúc training
-
cat_maps.pkl: Bản đồ mã hóa các biến phân loại → số nguyên
-
num_cols.pkl và cat_cols.pkl: Danh sách cột để tái tạo đúng đầu vào mô hình
Sử dụng mô hình để dự báo
Sau khi huấn luyện và lưu trữ toàn bộ mô hình cũng như thông tin tiền xử lý, bước tiếp theo là sử dụng chúng để dự báo doanh thu cho hàng trăm nghìn công ty trong tập dữ liệu chưa có nhãn.
Tải lại mô hình và thông tin tiền xử lý
Toàn bộ pipeline được khôi phục từ các file .pkl, .json, .pth:
1 | scaler = joblib.load("scaler.pkl") |
Khôi phục mô hình embedding
1 | embed_model = EmbeddingGenerator(cat_maps) |
Khôi phục mô hình XGBoost
1 | xgb_model = xgb.XGBRegressor() |
Dự báo theo từng batch
Vì dữ liệu lớn được chia thành các batch (processed_batch_000.csv đến processed_batch_489.csv), sử dụng vòng lặp để xử lý từng file đầu vào và tạo kết quả dự đoán.
Các bước thực hiện cho mỗi batch:
-
Bước 1: Đọc file dữ liệu đã xử lý.
-
Bước 2: Ánh xạ lại giá trị phân loại về dạng chỉ số (theo cat_maps).
-
Bước 3: Chuẩn hóa các giá trị số bằng StandardScaler.
-
Bước 4: Sinh embedding từ mô hình PyTorch.
-
Bước 5: Ghép đặc trưng số và embedding thành đầu vào cuối cùng.
-
Bước 6: Dự báo doanh thu với mô hình XGBoost.
1 | x_cat_tensor = torch.LongTensor(df[cat_cols].values) |
Dự đoán của mỗi batch được lưu lại cùng với corporate_number:
1 | batch_result = pd.DataFrame({ |
Gộp kết quả và xuất ra tệp duy nhất
Toàn bộ các kết quả từ các batch được hợp nhất lại để tạo thành một file .csv duy nhất:
1 | final_df = pd.concat(all_predictions, ignore_index=True) |
Kết quả cuối cùng này là dự đoán doanh thu cho toàn bộ doanh nghiệp trong hệ thống, và có thể dùng cho các mục đích:
-
Gợi ý kinh doanh hoặc tiếp thị tự động
-
Phân nhóm khách hàng theo tiềm năng
-
Tạo dashboard phân tích tài chính tự động
-
Dùng làm đầu vào cho các mô hình downstream như phân loại rủi ro
Deploy model lên torchserve
Mục đích là gọi model như gọi API, tạo thành luôn 1 service
Kiến trúc của torchserve:

1 | scp -r ./artifacts cty@ip:/home/cty/workspaces/salessmart_revenue |
1 | ssh cty@ip |
1 | cd /home/cty/workspaces/salessmart_revenue |
1 | artifacts config.properties hybrid_handler.py logs main.py model_def.py model_store pyproject.toml README.md uv.lock |
Tạo file config.properties
1 | number_of_gpu=1 |
Tạo file hybrid_handler.py
1 | import torch |
Create model_def.py
1 | import torch.nn as nn |
Create foldel model_store
1 | mkdir model_store |
Install package
1 | pip install pandas joblib scikit-learn xgboost |
1 | torch-model-archiver --model-name hybrid_revenue_model \ |
1 | torch-model-archiver --model-name hybrid_revenue_model \ |
Run
1 | torchserve --start --ncs --model-store model_store --models hybrid_revenue_model.mar --ts-config config.properties |
Test
1 | curl http://localhost:8081/models |
- good response:
1 | { |
1 | curl http://localhost:8080/ping |
- good response:
1 | { |
Curl
1 | http://ip:8580/predictions/hybrid_revenue_model |
- body:
1 | [ |
Kết quả
1 | [ |
Đánh giá kết quả
Giờ này, dự đoán ra rồi vậy làm sao để biết cái dự đoán đó nó có oke ko đối với 1 cty, tôi cần tìm 1 chỉ số để áng chừng chất lượng.
- Dựa vào đầu vào, tôi cho rằng nếu dữ liệu đầu vào bị null nhiều thì kết quả dự đoán ra sẽ không tốt. Tôi tính lại tỷ lệ số bản ghi không null và so sánh nó với độ lệch abs_error dự đoán


=> Kết quả trông nó cũng giống giống phân phối chuẩn 🙂
=> Cần tìm 1 chỉ số khác tỷ lệ nghịch với độ lệch dự đoán, tính trung bình nơi có sai số cao nhất 65%:
1 | mid_score = 65 |
Chuẩn hóa lại về dạng [0 - 1]
1 | from sklearn.preprocessing import MinMaxScaler |

=> Ta được một chỉ số khá là tuyến tính 🙂, chung cũng được
- Kết quả sau khi làm mịn

=> Tuy chưa oke nhưng mà chỉ số này có thể khăng định, nếu input_quality_percent mà cao thì độ lệch dự đoán thấp, còn input_quality_percent mà thấp hoặc tầm trung thì không kết luận được gì.
Kết luận
Do là dự án công ty nên tôi ko public tí hình ảnh nào ra đâu nha. Chỉ nói qua cách làm cho mọi người hình dung được thôi.
Tài liệu tham khảo
- Bài toán dự đoán doanh thu: https://legittai.com/blog/role-of-machine-learning-in-revenue-prediction-models
- Các thuật toán dùng cho bài toán:
https://www.researchgate.net/publication/376149539_Building_a_Revenue_Prediction_Model_Based_on_Machine_Learning_Tuning_Methods - https://docs.pytorch.org/serve/token_authorization_api.html?highlight=disable_token_authorization
- https://codelabs.developers.google.com/codelabs/how-to-use-stable-diffusion-cloud-run-gpu?hl=vi#2
- https://viblo.asia/p/model-serving-trien-khai-machine-learning-model-len-production-voi-tensorflow-serving-deploy-machine-learning-model-in-production-with-tensorflow-serving-XL6lAvvN5ek
- https://viblo.asia/p/torchserve-cong-cu-ho-tro-trien-khai-mo-hinh-pytorch-vyDZOqwO5wj
- bank
- bank