Sagemaker Batch Transform
About Sagemaker
Sagemaker allows for simplified deployment of machine learning models with ease. When training a model, you want to call Sagemaker with some input data. Here, Sagemaker provides 4 cost and limit options:
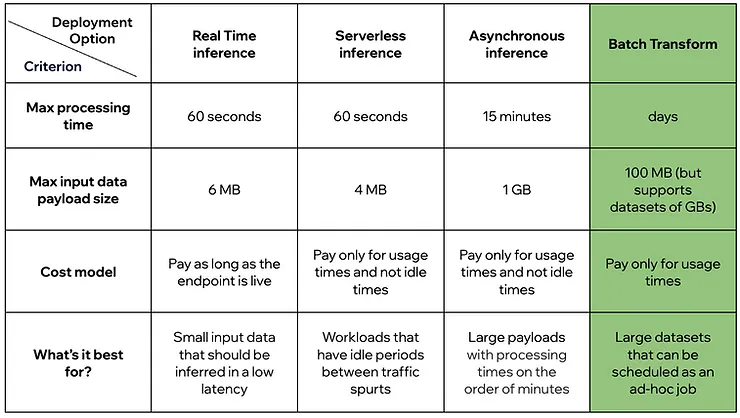
Sagemaker Batch Transform
Introduction
SageMaker Batch Transform is a batch inference service used to run ML models on existing datasets, saving results directly to S3. It’s suitable for scenarios that don’t require low latency and need to process large volumes of data in batches.
Using Batch Transform eliminates the need to maintain a continuous endpoint and is only needed when performing inference on a dataset at specific times. Sagemaker Batch Transform is a serverless, scalable, and cost-effective solution for running batch inferences on large datasets.
=> Sagemaker Batch Transform = ECS + S3
Concepts
- Run inference in batches rather than real-time requests.
- Read input data from S3 and write results to S3 as files.
- No need to deploy Endpoints, only runs when there’s a job, optimizing costs for periodic processing.
One inference for one model:
- model_fn
- input_fn
- predict_fn
- output_fn
Minimum components to create a Sagemaker Batch Transform Job are as follows:
sagemaker_client = boto3.client('sagemaker')
request = {
"TransformJobName": batch_job_name,
"ModelName": model_name,
"MaxPayloadInMB": payload_size,
"BatchStrategy": "MultiRecord",
"MaxConcurrentTransforms": max_concurrent_tranform_jobs,
"Environment": environment_variables,
"TransformInput": {
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": input_s3_path
}
},
"ContentType": "text/csv",
"SplitType": "Line",
"CompressionType": "None"
},
"TransformOutput": {
'S3OutputPath': output_s3_path,
},
"TransformResources": {
"InstanceType": instance_type,
"InstanceCount": instance_count
}
}
sagemaker_client.create_transform_job(**request)
The configuration specifies the following information:
- “TransformJobName”: Unique name of the batch transform job.
- “ModelName”: Name of the pre-trained model to be used for inference. This model references the Docker image used to serve the model, created model artifacts, and declared environment variables.
- “BatchStrategy”: Batch strategy for performing inference, can be
"SingleRecord"or"MultiRecord". - “MaxConcurrentTransforms”: Maximum number of inferences that can run simultaneously.
- “Environment”: A dictionary containing environment variables that will be passed to EC2 instances.
- “TransformInput”: Input data for the batch transform job, including S3 location, data type, content type, and compression type.
- “TransformOutput”: S3 location to store the results of the batch transform job.
- “TransformResources”: EC2 resources used for the batch transform job, including instance type and instance count.
What happens when creating a Batch Transform Job?
Below are the steps that AWS Sagemaker will perform during the batch transform process:
Initialize EC2
Sagemaker will launch a special EC2 instance according to parameters specified inTransformResources.Set up environment using Docker image
The instance will be configured with the Docker image that theModelobject references.Load environment variables
Sagemaker will load environment variables into the instance.- Note: The
Modelobject may also contain its own environment variables. - If the same environment variable is defined in both
Modeland in thecreate_transform_jobparameter, the final value will be taken fromcreate_transform_job.
- Note: The
Health check
Sagemaker sends a ping request to check the instance status:- If it doesn’t pass the check, the job will fail with error status.
- If successful, the process moves to the next step.
Determine input data
Through theTransformInputparameter, Sagemaker determines the data to be processed.Perform inference
Based on parameters likeMaxConcurrentTransforms,BatchStrategy, andMaxPayloadInMB, Sagemaker starts sending input data to the/invocationendpoint of the instance to perform predictions.- If these parameters are not provided in
create_transform_job(), Sagemaker will try to get them from the/execution-parametersendpoint of the created instance. - If this endpoint doesn’t exist, Sagemaker will use default values.
- If these parameters are not provided in
Save prediction results
All results will be saved according to the configuration in theTransformOutputparameter.Stop instance
After completion, Sagemaker will stop the instance.
Important Notes
Sagemaker splits input data blindly, without considering our specific logic. This can cause errors if the data has headers, as only the first part retains the header, while the rest lose it, leading to Batch Transform job failure.
Solutions:
Avoid using feature names in inference, just maintain the correct column order same as training data.
Manually split data into multiple files, each with headers, then provide these multiple files to Batch Transform (each input file will have separate output).
Real-world Applications
- Labeling/inference for historical data warehouse (e.g., app reviews collected on S3).
- Creating advanced feature enrichment for analysis report pipelines.
- Classification, topic/sentiment detection, large-scale content filtering.
- Re-running inference in batches when there’s a new model version.
Important:
Batch Transform does not support CSV input data containing newline characters within the same cell.
You can adjust mini-batch size by configuring BatchStrategy and MaxPayloadInMB parameters.
MaxPayloadInMB value must not exceed 100 MB.
If you use the additional MaxConcurrentTransforms parameter, ensure the formula:
MaxConcurrentTransforms × MaxPayloadInMB ≤ 100 MB |