DistilBERT-SST2 Model
DistilBERT-SST2 Model
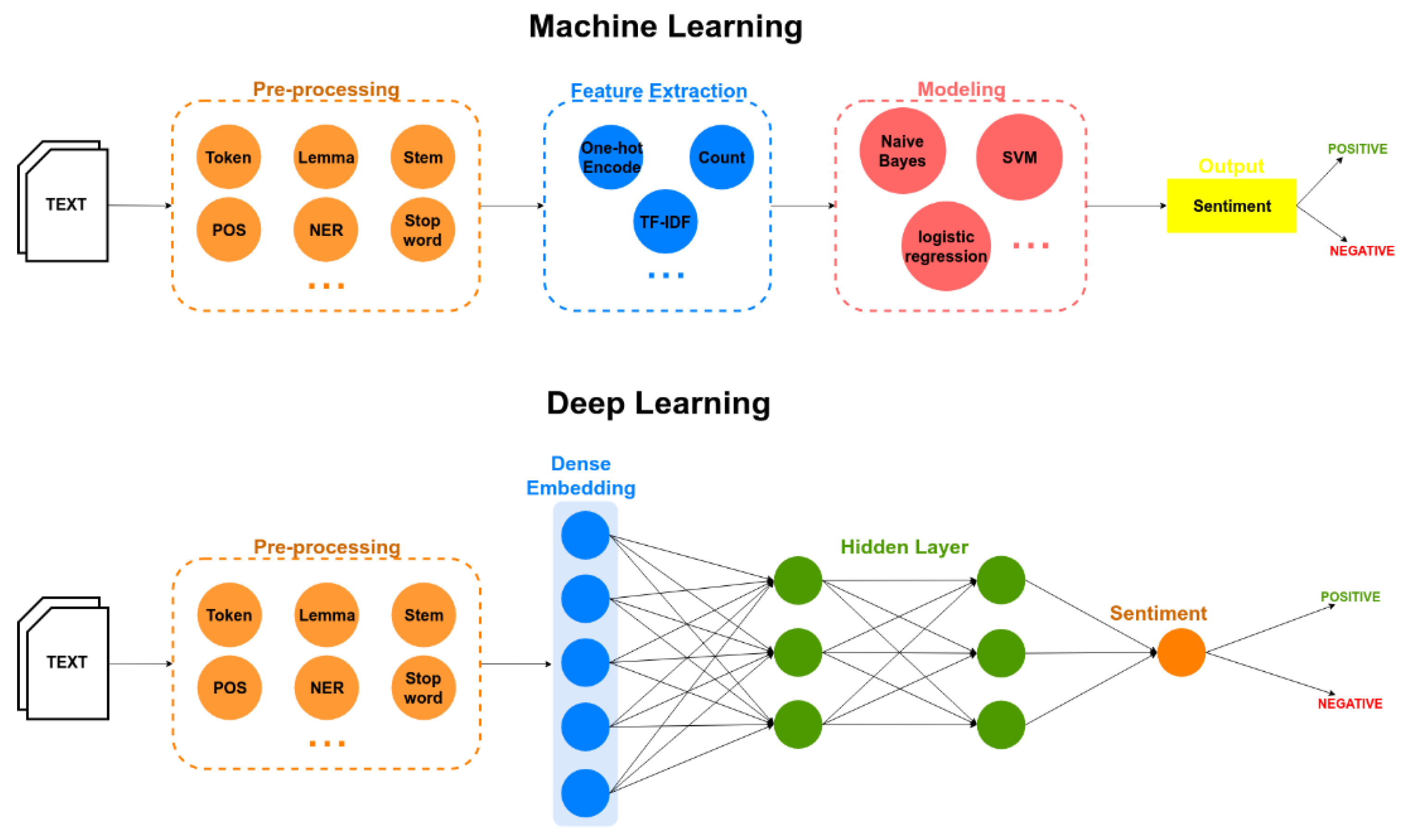
Introduction
DistilBERT-SST2 is a DistilBERT model fine-tuned on the SST-2 dataset for binary sentiment analysis (positive/negative) at the sentence level. The model is compact, fast inference, with good accuracy for common sentiment analysis tasks.
Concepts
- DistilBERT is a distilled version of BERT through knowledge distillation technique: fewer parameters (~40% less), faster inference (up to ~60% faster) while retaining most of BERT’s performance.
- SST-2 (Stanford Sentiment Treebank v2) assigns binary sentiment labels to sentences; the model output is probability/label of Positive or Negative.
- Results are typically obtained using Softmax over two classes; thresholds can be adjusted for different business objectives.
Text Classification into Positive/Negative
The reason for using this model is that the collected data has a content column containing user reviews.
Quick Implementation
Hugging Face Transformers:
from transformers import pipeline
classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english")
print(classifier("This product is awesome!"))
Output: {'label': 'POSITIVE', 'score': 0.999}
Easy deployment in Flask/FastAPI to create APIs for real-time serving.
Real-world Applications
- Sentiment analysis of app reviews, customer feedback, social media posts.
- Early warning and prioritization of negative feedback processing in support workflows.
- Monitoring sentiment trends over time for brand/product reporting.
- Preprocessing step for advanced pipelines: topic classification, ticket routing, summarization.