Crawl Data
Crawl Data
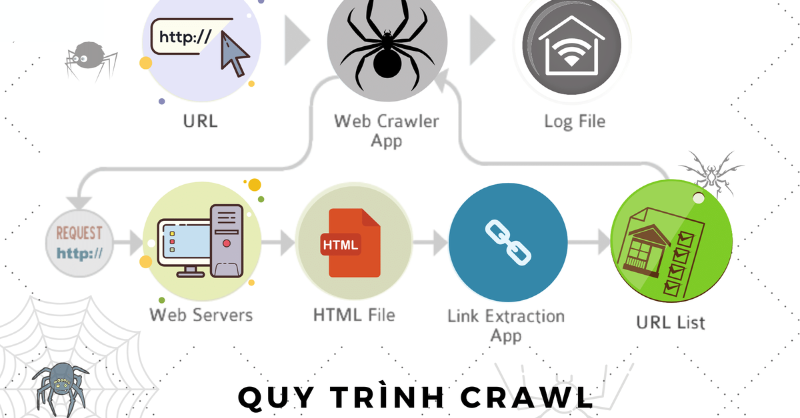
Crawling data is the process of automatically collecting information from websites on the Internet. To understand how it works, imagine you have a bot on the web whose job is to grab anything useful it finds.
The bot starts by navigating through web pages, much like a traveler exploring roads on a map. When it arrives at a page, it scans the page’s content and inspects DOM elements—analyzing links, text, images, videos, and structured data.
It then extracts the information of interest—similar to taking notes of key points while reading a book. This data can be text, images, videos, or structured data like tables.
The process continues until the bot has gathered enough information or has visited all pages in its list. For websites that frequently update content, you can schedule the bot to repeat the crawl periodically to ensure your dataset is always up-to-date.
However, crawling must be done carefully and in compliance with copyright laws and the privacy policies of the websites. Violating these rules may result in legal consequences. A common best practice is to check the robots.txt file before crawling.
A seasoned data crawler often says: “Anything visible on the web can be retrieved with code.”
Methods of Crawling Data
Using AI
With the rise of large language models, AI-based crawling is no longer unfamiliar.
Popular tools include:
- Firecrawl
- Apify
- Rapid
- Data Miner
➡️ Convenient and fast, but usually requires paid usage.
Traditional Approaches
- Puppeteer
- Selenium
- Scrapy
- BeautifulSoup (Bs4)
- Playwright
➡️ More complex, requires coding and setting up infrastructure to use.